
n8n error handling best practices in hindi:एक ऑटोमेशन वर्कफ़्लो बनाना जो आपके टेस्ट लैब के स्थिर और पूर्वानुमानित वातावरण में सही ढंग से काम करे, अपेक्षाकृत आसान है। यह आसान हिस्सा है।
लेकिन वही वर्कफ़्लो वास्तविक दुनिया में काम करे—जहाँ उपयोगकर्ता अजीबोगरीब हरकतें कर सकते हैं, API अचानक काम करना बंद कर सकते हैं, या सर्वर कभी-कभी क्रैश हो सकते हैं—तो यह पूरी तरह अलग चुनौती है।
यही है त्रुटि प्रबंधन (Error Handling) की कला।
यह वह सबसे महत्वपूर्ण कौशल है जो शौकिया स्वचालन निर्माताओं को उन पेशेवरों से अलग करता है, जो आत्मविश्वास के साथ हजारों वास्तविक कार्यों को संभालने वाले सिस्टम को तैनात कर सकते हैं और फिर भी रात को चैन की नींद ले सकते हैं।

What “Production Ready” Actually Means (And Why Your Automation Workflow Probably Isn’t)
चलिये एक उदाहरण से समझते हैं। आपने पिछले हफ्ते n8n में अपना अब तक का सबसे बेहतरीन ऑटोमेशन वर्कफ़्लो बनाया है। टेस्ट में यह शानदार ढंग से काम कर रहा है और आपका सैंपल डेटा इसे बिना किसी त्रुटि के हैंडल कर रहा है। आप खुद को एक प्रमाणित ऑटोमेशन विशेषज्ञ महसूस कर रहे हैं।
तो, गर्व से भरकर आप ऊपरी दाएं कोने में मौजूद छोटे से स्विच को “निष्क्रिय” से “सक्रिय” कर देते हैं।
और तभी… आपदा आ पड़ती है।
एक असली उपयोगकर्ता डेटा दर्ज करता है, जिसमें एक अजीब सा इमोजी शामिल होता है—जिसका आपने पहले ध्यान नहीं रखा था। उसी समय, जिस थर्ड-पार्टी API पर आप निर्भर हैं, उसमें क्षणिक गड़बड़ी आ जाती है। किसी सेवा के लिए आपके क्रेडेंशियल समाप्त हो जाते हैं।
और आपका सुंदर, सुव्यवस्थित वर्कफ़्लो न केवल विफल होता है, बल्कि पूरी तरह ध्वस्त हो जाता है, हज़ारों रिकॉर्ड नष्ट हो जाते हैं और आपको पता भी नहीं चलता।
यह याद रखें—“उत्पादन के लिए तैयार” होने का मतलब सिर्फ यह नहीं कि टेस्ट के दौरान सब सही चल रहा था। इसका असली मतलब है कि आपने एक मजबूत, एंटी-फ्रैजाइल सिस्टम तैयार किया है।
इसका अर्थ है:
- आपका वर्कफ़्लो सिस्टम को पूरी तरह ध्वस्त किए बिना, त्रुटियों को सुचारू रूप से संभाल सकता है।
- किसी महत्वपूर्ण घटना में गलती होने पर आपको तुरंत नोटिफिकेशन मिलती है।
- त्रुटियों को बुद्धिमानी से लॉग किया जाता है, जिससे डिबगिंग आसान और स्पष्ट हो जाती है, न कि रहस्यमयी।
- सिस्टम में रिट्राई और फॉलबैक लॉजिक मौजूद है—एक अंतर्निहित “प्लान बी”।
- सबसे महत्वपूर्ण: यदि विफलता होती भी है, तो यह सुरक्षित रूप से विफल होती है, बिना हज़ारों गलत ईमेल भेजे या डेटाबेस से महत्वपूर्ण डेटा खोए।

किसी भी उत्पादन (प्रोडक्शन) परिवेश की कठोर सच्चाई यह है कि विफलताएँ सिर्फ संभव नहीं, बल्कि अपरिहार्य हैं।
इसलिए आपका लक्ष्य ऐसा सिस्टम बनाना नहीं है जो कभी विफल न हो—क्योंकि ऐसा असंभव है।
आपका असली काम है ऐसा सिस्टम बनाना जो समझदारी से विफल हो, यानी विफल होने पर भी नुकसान न्यूनतम हो, त्रुटियों का पता तुरंत चले, और सिस्टम सुरक्षित रहे।
The “Onion” of a Professional Workflow: The Error Handling Hierarchy
इन पांच तकनीकों को आप प्याज की परतों या लगातार मजबूत होते कवच के स्तरों के रूप में समझ सकते हैं।
- एक सरल वर्कफ़्लो में शायद सिर्फ एक या दो सुरक्षा परतें ही पर्याप्त हों।
- लेकिन एक जटिल, मिशन-महत्वपूर्ण सिस्टम अक्सर इन सभी पांच तकनीकों का उपयोग करता है, और ये एक-दूसरे के साथ पूरी सामंजस्य में काम करती हैं।
ये पाँच सुरक्षा परतें हैं:
- त्रुटि वर्कफ़्लो (Error Workflow) – मास्टर सुरक्षा जाल, जो किसी भी समस्या का पहला बचाव है।
- असफलता पर पुनः प्रयास (Retry on Failure) – “दूसरा मौका” बटन, जो अस्थायी विफलताओं को संभालता है।
- फॉलबैक LLM (Fallback LLM) – बैकअप ब्रेन, जब मुख्य एल्गोरिथ्म फेल हो।
- त्रुटि होने पर भी जारी रखें (Continue on Error) – “शो जारी रहना चाहिए” प्रोटोकॉल, जिससे सिस्टम का मुख्य काम प्रभावित न हो।
- मतदान (Voting / The Patient Watcher) – एक अंतिम जाँच और संतुलन, जो सुनिश्चित करता है कि निर्णय सही तरीके से लिया जाए।

Technique #1: Error Workflows (Your Automation Insurance Policy)
यह पहली तकनीक सबसे महत्वपूर्ण है। यह किसी भी गंभीर स्वचालन (ऑटोमेशन) निर्माता के लिए मूलभूत सुरक्षा कवच है। इसके बिना, आप ऐसे हैं जैसे अंधेरे में तीर चला रहे हों।
समस्या: “खामोश हत्यारा”
वर्कफ़्लो की विफलता का सबसे खतरनाक पहलू अक्सर विफलता स्वयं नहीं, बल्कि उसकी खामोशी होती है।
उदाहरण के तौर पर, मान लीजिए आपके पास एक ऑटोमेशन है जो हर रात 100 नए लीड्स प्रोसेस करता है। अगर किसी थर्ड-पार्टी API में बदलाव हो जाता है या कोई क्रेडेंशियल एक्सपायर हो जाता है, तो आपका वर्कफ़्लो एक हफ्ते तक हर रात विफल हो सकता है, और हज़ारों मूल्यवान लीड्स चुपचाप खो जाते हैं।
आपको इसका पता तब चलेगा जब महीने के अंत में अपने सेल्स डेटा की समीक्षा करेंगे और सोचेंगे, “ये आंकड़े अचानक इतनी तेज़ी से क्यों घट गए?”

The Solution: A Centralized “Mission Control” for Errors
पेशेवर समाधान यह सुनिश्चित करना है कि कोई भी विफलता चुपचाप न हो।
इसके लिए एक केंद्रीकृत त्रुटि वर्कफ़्लो (Centralized Error Workflow) बनाया जाता है। इसे आप अपने पूरे n8n ऑपरेशन के लिए “मिशन कंट्रोल” या सेंट्रल सिक्योरिटी डेस्क की तरह समझ सकते हैं।
कल्पना कीजिए कि आपके द्वारा बनाए गए प्रत्येक वर्कफ़्लो को एक अलग- अलग कमरा कहा जाए। आपका लक्ष्य यह है कि हर कमरे से फायर अलार्म इस केंद्रीय डेस्क से जुड़ा हो। यानी, किसी भी कमरे में समस्या होने पर आपको तुरंत पता चल जाए और आप कार्रवाई कर सकें।

Building Your “Mission Control” for Errors: A 3-Step Guide
चरण 1: “आपातकालीन प्रतिक्रिया टीम” वर्कफ़्लो बनाना
n8n में एक बिलकुल नया और अलग वर्कफ़्लो बनाकर शुरुआत करें।
- सबसे पहला नोड जो आप जोड़ेंगे वह “त्रुटि ट्रिगर (Error Trigger)” नोड होगा।
- यह विशेष ट्रिगर सिर्फ़ आपके अन्य वर्कफ़्लो से आने वाले विफलता संकेतों को सुनता है।
- इस पूरे वर्कफ़्लो का एकमात्र उद्देश्य है आपातकालीन संकेतों को तुरंत पहचानना और संभालना।
चरण 2: “रेड फ़ोन” को कनेक्ट करना
अब आपको अपने सभी वर्कफ़्लो को इस नई आपातकालीन लाइन से जोड़ना होगा।
- अपने n8n इंस्टेंस में मौजूद प्रत्येक सक्रिय वर्कफ़्लो के सेटिंग्स पैनल में जाएँ।
- वहाँ आपको “एरर वर्कफ़्लो” नाम का एक फ़ील्ड मिलेगा।
- इस ड्रॉपडाउन से आप अभी बनाए गए “आपातकालीन प्रतिक्रिया टीम (Emergency Response Team)” वर्कफ़्लो का चयन करें।
इस प्रक्रिया को आप ऐसे समझ सकते हैं जैसे हर विभाग में एक रेड इमरजेंसी फ़ोन लगाया गया हो, जो सीधे आपके केंद्रीय सुरक्षा डेस्क से जुड़ा हो।
चरण 3: “अलर्ट और लॉग” प्रोटोकॉल तैयार करना
अब अपने एरर वर्कफ़्लो के अंदर एक परिष्कृत प्रोटोकॉल डिज़ाइन करें, जो यह तय करे कि त्रुटि का पता चलने पर क्या होता है।
एक पेशेवर एरर वर्कफ़्लो आम तौर पर दो महत्वपूर्ण काम करता है:
- सभी विवरणों को रिकॉर्ड करना
- विफलता से महत्वपूर्ण डेटा निकालें: विफल वर्कफ़्लो का नाम, सटीक त्रुटि संदेश, विफल नोड का नाम, और यहां तक कि त्रुटि का कारण बनने वाला इनपुट डेटा।
- इसे Google Sheets, Airtable, या किसी अन्य संरचित डेटाबेस में स्टोर करें।
- इससे एक अमूल्य लॉग तैयार होता है, जो डिबगिंग और भविष्य की जांच के लिए बेहद उपयोगी होता है।
- स्मार्ट नोटिफिकेशन भेजना
- एक स्पष्ट और प्राथमिकता-आधारित नोटिफिकेशन सीधे जिम्मेदार व्यक्ति को भेजें।
- यह नोटिफिकेशन ईमेल हो सकता है, या ज़रूरत पड़ने पर स्लैक चैनल में डायरेक्ट मैसेज भी हो सकता है।
इस तरह, आपकी टीम तुरंत समस्या की जानकारी पा सकती है और समय रहते सुधारात्मक कदम उठा सकती है।

A Real-World Example: The Airtable Credential Failure
मान लीजिए आपके पास एक एजेंट वर्कफ़्लो है जो नए लीड्स को Airtable डेटाबेस में दर्ज करता है। एक दिन, आपकी Airtable API कुंजी की समय सीमा समाप्त हो जाती है।
- त्रुटि रहित वर्कफ़्लो:
वर्कफ़्लो हर बार चुपचाप विफल हो जाता है। कई दिनों तक संभावित ग्राहक खो जाते हैं और आपको पता भी नहीं चलता कि यह क्यों हो रहा है। - त्रुटि वर्कफ़्लो के साथ:
जैसे ही पहली लीड Airtable में दर्ज होने में विफल होती है, आपका मिशन कंट्रोल वर्कफ़्लो तुरंत सक्रिय हो जाता है।
आपको तुरंत एक स्लैक संदेश प्राप्त होता है, जिसमें लिखा होता है:
” ALERT: Airtable API कुंजी एक्सपायर हो गई है। नया लीड रिकॉर्ड दर्ज नहीं हो सका। कृपया API कुंजी अपडेट करें और वर्कफ़्लो को पुनः सक्रिय करें।”
इस तरह, आप समस्याओं का तुरंत पता लगाते हैं और समय रहते कार्रवाई कर सकते हैं, जिससे डेटा और संभावित अवसरों की हानि से बचा जा सकता है।
इस प्रकार, एक खामोश और विनाशकारी विफलता तुरंत एक कार्रवाई योग्य चेतावनी में बदल जाती है।
आप समस्या को सिर्फ़ पाँच मिनट में ठीक कर सकते हैं, इससे पहले कि यह हज़ारों रिकॉर्ड्स या महत्वपूर्ण डेटा को प्रभावित करे।
Pro-Level Upgrade: “Tiered Alerting”
सभी विफलताएँ एक जैसी नहीं होतीं।
- आपके मिशन-क्रिटिकल वर्कफ़्लो जैसे “ग्राहक भुगतान प्रसंस्करण” में विफलता गंभीर समस्या है।
- वहीं, नॉन-क्रिटिकल वर्कफ़्लो जैसे “दैनिक समाचार सारांश” में विफलता मामूली समस्या है, जिसे बाद में हल किया जा सकता है।
आप इन परिस्थितियों को अलग-अलग तरीके से संभालने के लिए अपने एरर वर्कफ़्लो में लॉजिक जोड़ सकते हैं।
- आप एक “स्विच” नोड का उपयोग कर सकते हैं, जो विफल वर्कफ़्लो का नाम देखता है।
- अगर यह महत्वपूर्ण वर्कफ़्लो है, तो यह Slack @channel में उच्च प्राथमिकता वाला अलर्ट भेज सकता है और आपके फोन पर पुश नोटिफिकेशन ट्रिगर कर सकता है।
- अगर यह गैर-महत्वपूर्ण वर्कफ़्लो है, तो यह बस आपके लिए एक स्प्रेडशीट में एक नई पंक्ति जोड़ सकता है, जिसे आप अपने खाली समय में देख सकते हैं।
इस तरह आप सिस्टम की गंभीर और मामूली त्रुटियों को अलग-अलग तरीके से मैनेज कर सकते हैं, बिना किसी महत्वपूर्ण डेटा या समय को खोए।
इस तरह, आप एक स्मार्ट अलर्ट सिस्टम बना सकते हैं जो आपके समय और ध्यान का सम्मान करता है। यह आपको केवल वास्तव में महत्वपूर्ण घटनाओं के लिए ही सूचित करता है, जबकि मामूली त्रुटियाँ चुपचाप संभाली जाती हैं।
यदि आप इसे चरण-दर-चरण सेटअप के साथ सीखना चाहते हैं, तो YouTube पर “n8n error workflow” खोजें। वहाँ कई बेहतरीन ट्यूटोरियल उपलब्ध हैं जो आपको व्यावहारिक उदाहरणों के साथ गाइड करेंगे।
Technique #2: The “Turn It Off and On Again” Button (Retry on Failure)
सच कहें तो, तकनीकी दुनिया में सबसे कारगर और आजमाया हुआ समाधान यही है:
“क्या आपने इसे बंद करके फिर से चालू किया?”
यह अब एक मज़ाक बन चुका है, लेकिन इसके पीछे एक गहरी वजह है।
तकनीकी खराबियों का बड़ा हिस्सा अस्थायी और क्षणिक अड़चनें होती हैं—जैसे:
- नेटवर्क में थोड़ी देर के लिए समस्या होना
- सर्वर पर अस्थायी ज्यादा भार पड़ना
- किसी सर्वर रैक में सूक्ष्म कारणों से बिट का अस्थायी भ्रष्ट होना
इनमें से कई समस्याएँ सरल रीस्टार्ट या रिट्राई से तुरंत ठीक हो जाती हैं, यही वजह है कि यह पुराना समाधान अब भी बेहद प्रभावी माना जाता है।

एक सामान्य, शौकिया वर्कफ़्लो में यदि ऐसी कोई समस्या आती है, तो वह तुरंत रुक जाता है और पूरी प्रक्रिया विफल हो जाती है।
लेकिन एक पेशेवर वर्कफ़्लो में, इस प्रसिद्ध तकनीकी सहायता सलाह का स्वचालित विकल्प पहले से ही मौजूद होता है।
इसे कहते हैं: “विफलता पर पुनः प्रयास करें (Retry on Failure)”।
यह सुविधा आपकी पहली और सबसे प्रभावी सुरक्षा पंक्ति है, जो यह सुनिश्चित करती है कि अस्थायी त्रुटियाँ आपकी पूरी प्रक्रिया को विफल न कर पाएं।
How to Set It Up: A 30-Second Fix for 70% of Your Problems
यह शानदार फीचर n8n के लगभग हर नोड में अंतर्निहित है, चाहे वह कोई एआई एजेंट हो या साधारण HTTP अनुरोध।
- अपने वर्कफ़्लो में किसी भी नोड की सेटिंग्स खोलें।
- सेटिंग्स पैनल में आपको “असफल होने पर पुनः प्रयास करें (Retry on Failure)” का विकल्प मिलेगा। इसे चालू करें।
इससे दो महत्वपूर्ण विकल्प सामने आते हैं:
- अधिकतम प्रयास (Maximum Attempts)
- यह बताता है कि नोड को अंततः हार मानने से पहले कितनी बार क्रिया को पुनः प्रयास करना चाहिए।
- एक अच्छा डिफ़ॉल्ट मान है 3–5 प्रयास।
- प्रतीक्षा समय (Wait Time)
- यह प्रत्येक पुनः प्रयास के बीच का विलंब दर्शाता है, सेकंड में।
इस तरह, अस्थायी समस्याएँ स्वतः संभल जाती हैं और आपका वर्कफ़्लो बिना किसी हस्तक्षेप के जारी रह सकता है।
बस इतना ही! दो क्लिक और दो नंबरों के साथ, आपने संभवतः ऐसा सिस्टम बना लिया है जो अधिकांश उत्पादन विफलताओं को स्वतः संभाल सकता है और उनसे जल्दी उबर सकता है।
पुनः प्रयास की कला: एक रणनीतिक मार्गदर्शिका
सभी पुनः प्रयास समान नहीं होते। पुनः प्रयास की इष्टतम संख्या और आदर्श प्रतीक्षा समय उस कार्य के प्रकार पर निर्भर करता है जो नोड कर रहा है।
बाहरी API कॉल के लिए:
- ये विफलताओं के सबसे आम बिंदु हैं।
- एक अच्छी रणनीति है कि 3–5 बार पुनः प्रयास करें, प्रत्येक प्रयास के बीच 5 सेकंड का अंतराल रखें।
- इससे थर्ड-पार्टी सर्वर (जिस पर आपका नियंत्रण नहीं है) को क्षणिक ओवरलोड या छोटे नेटवर्क इश्यू से उबरने के लिए पर्याप्त समय मिल जाता है।
इस तरह, आपका वर्कफ़्लो अस्थायी त्रुटियों से सुरक्षित रहता है और लगातार संचालन जारी रख सकता है।
एआई मॉडल के लिए:
- इन विफलताओं का कारण अक्सर सर्वर लोड होता है।
- एक अच्छी रणनीति है कि 2–3 बार पुनः प्रयास करें, प्रत्येक प्रयास के बीच 5 सेकंड का अंतराल रखें।
- अक्सर एक त्वरित पुनः प्रयास ही पर्याप्त होता है।
- यदि कोई एआई मॉडल लगातार तीन बार विफल हो जाता है, तो संभावना है कि यह कोई बड़ी समस्या है—जैसे कोई बड़ा आउटेज—जिसे अधिक बार पुनः प्रयास करने से हल नहीं किया जा सकता।
इस तरह, आप अपने वर्कफ़्लो को अस्थायी समस्याओं और गंभीर आउटेज दोनों के लिए स्मार्ट तरीके से तैयार कर सकते हैं।
फ़ाइल संचालन के लिए
- जब आप स्थानीय या नेटवर्क फ़ाइल सिस्टम के साथ काम करते हैं, तो कभी-कभी कोई फ़ाइल किसी अन्य प्रक्रिया द्वारा अस्थायी रूप से लॉक हो जाती है।
- ये समस्याएँ अक्सर कुछ ही सेकंड में हल हो जाती हैं।
- ऐसी स्थिति में, 1–2 सेकंड के छोटे अंतराल के साथ 5 बार से अधिक पुनः प्रयास करना एक अच्छी रणनीति है।
OpenAI की गड़बड़ी: एक वास्तविक दुनिया का उदाहरण
कल्पना कीजिए कि आपका वर्कफ़्लो किसी टेक्स्ट को सारांशित करने के लिए OpenAI API को कॉल कर रहा है।
लेकिन उसी समय, उनके सर्वरों पर ट्रैफ़िक अचानक बढ़ जाता है और अनुरोध विफल हो जाता है।
- विफलता पर पुनः प्रयास न होने पर:
आपका पूरा वर्कफ़्लो तुरंत रुक जाता है, त्रुटि दर्ज होती है और कार्य अधूरा रह जाता है। - विफलता पर पुनः प्रयास के साथ (3 पुनः प्रयास, 5 सेकंड का इंतजार):
- पहला प्रयास: सर्वर की अस्थायी गड़बड़ी के कारण विफल। नोड ने हार नहीं मानी और 5 सेकंड प्रतीक्षा की।
- दूसरा प्रयास: सर्वर अभी भी व्यस्त। यह फिर विफल हो गया। नोड ने 5 सेकंड और प्रतीक्षा की।
- तीसरा प्रयास: ट्रैफ़िक सामान्य हो गया। एपीआई कॉल सफल रही।
इस तरह, कार्यप्रवाह सामान्य रूप से जारी रहता है, मानो कोई समस्या हुई ही न हो।
उपयोगकर्ता अनुभव:
- उपयोगकर्ता को कभी कोई त्रुटि दिखाई नहीं देती।
- प्रक्रिया सफलतापूर्वक पूरी हो जाती है।
- यही है एक मजबूत, स्वतः ठीक होने वाली प्रणाली बनाने की वास्तविक शक्ति।
प्रो-लेवल अपग्रेड: “एक्सपोनेंशियल बैकऑफ़” रणनीति
अपने सबसे महत्वपूर्ण API कॉल्स के लिए, आप Google और Amazon जैसी बड़ी कंपनियों द्वारा इस्तेमाल की जाने वाली उन्नत रिट्राई रणनीति लागू कर सकते हैं: एक्सपोनेंशियल बैकऑफ़।
- पारंपरिक पुनः प्रयास में, प्रत्येक प्रयास के बीच समान विलंब होता है, जैसे 10 सेकंड।
- एक्सपोनेंशियल बैकऑफ़ में, प्रत्येक पुनः प्रयास के बीच विलंब तेजी से बढ़ता है, जिससे सर्वर पर दबाव कम होता है और क्षणिक गड़बड़ियाँ आसानी से संभल जाती हैं।
उदाहरण:
- पुनः प्रयास #1: 5 सेकंड प्रतीक्षा
- पुनः प्रयास #2: 10 सेकंड प्रतीक्षा
- पुनः प्रयास #3: 20 सेकंड प्रतीक्षा
इस तरह, आपका वर्कफ़्लो अस्थायी सर्वर लोड या नेटवर्क समस्या से सुरक्षित रहता है और लगातार संचालन जारी रख सकता है।
यह बुद्धिमत्तापूर्ण दृष्टिकोण संघर्षरत सर्वर को रिकवर होने के लिए पर्याप्त समय देता है।
- हालाँकि n8n का अंतर्निहित रिट्राई रैखिक है,
- आप कुछ अतिरिक्त नोड्स का उपयोग करके अपने सबसे महत्वपूर्ण API कॉल्स के लिए कस्टम एक्सपोनेंशियल बैकऑफ़ लूप बना सकते हैं।
- यह पूरी तरह त्रुटिरहित ऑटोमेशन तैयार करने की एक पेशेवर तकनीक है।
तकनीक #3: फॉलबैक एलएलएम (आपके एआई का बैकअप गायक)
“असफलता होने पर पुनः प्रयास करें” तकनीक आपकी पहली सुरक्षा पंक्ति है। यह अस्थायी, स्वतः ठीक होने वाली समस्याओं के लिए उपयुक्त है।
लेकिन अगर समस्या गंभीर हो—जैसे आपका प्राथमिक एआई मॉडल पूरी सेवा के लिए ठप हो जाए—तो साधारण पुनः प्रयास लूप मदद नहीं करेगा।
यहीं पर आता है आपका ठोस प्लान बी।
इसे इस तरह समझिए:
- आपका प्राथमिक एआई मॉडल आपके बैंड का मुख्य गायक है—प्रतिभाशाली और करिश्माई।
- लेकिन अगर हाउसफुल शो से ठीक पहले वह अचानक गले में खराश कर बैठता है, तो क्या होगा? शौकिया शो रद्द हो जाएगा।
- वहीं, एक पेशेवर शो हमेशा एक प्रतिभाशाली बैकअप गायक तैयार रखता है, जो किसी भी क्षण उसकी जगह ले सकता है ताकि शो बिना रुकावट जारी रहे।
इसी तरह, आपका फॉलबैक एलएलएम किसी भी गंभीर एआई आउटेज में आपके वर्कफ़्लो को चलाता रहता है और निरंतर संचालन सुनिश्चित करता है।

फॉलबैक एलएलएम: आपका एआई बैकअप मॉडल
फॉलबैक एलएलएम वह द्वितीयक एआई मॉडल है, जिस पर आपका वर्कफ़्लो स्वचालित रूप से स्विच कर सकता है यदि प्राथमिक मॉडल विफल हो जाए।
- इससे यह सुनिश्चित होता है कि किसी बड़ी सेवा रुकावट के दौरान भी आपका स्वचालन बिना रुकावट चलता रहे।
इसे कैसे सेटअप करें: अपनी “प्लान बी” कॉन्फ़िगर करना
- यह सुविधा सीधे n8n के AI एजेंट नोड में अंतर्निहित है (नवीनतम n8n संस्करण आवश्यक)।
- सेटअप बेहद सरल है:
- अपने AI एजेंट नोड में जाएँ और सेटिंग्स टैब खोलें।
- सुनिश्चित करें कि “असफल होने पर पुनः प्रयास करें” विकल्प चालू हो।
- फिर पैरामीटर्स टैब में जाएँ और आपको “Add Fallback Model” नामक विकल्प दिखाई देगा। इसे चेक करें।
इस तरह, आपका वर्कफ़्लो स्वचालित रूप से बैकअप मॉडल पर स्विच कर सकता है और निरंतर संचालन सुनिश्चित करता है।
एक नया कनेक्शन फ़ील्ड दिखाई देगा, जिससे आप एक अलग एआई मॉडल को अपने बैकेप मॉडल के रूप में जोड़ सकते हैं।
- इसका मतलब यह है कि यदि आपका प्राथमिक एआई मॉडल किसी कारणवश विफल हो जाता है, तो आपका वर्कफ़्लो स्वचालित रूप से इस बैकअप मॉडल पर स्विच कर लेगा।
- इस सेटअप से आपका ऑटोमेशन लगातार और सुरक्षित चलता रहता है, भले ही मुख्य मॉडल अस्थायी रूप से अनुपलब्ध हो।
बैकअप प्लान की कला: एक रणनीतिक मार्गदर्शिका
बैकअप मॉडल चुनना केवल किसी और एआई को चुनने जैसा नहीं है; यह एक सावधानीपूर्वक रणनीतिक निर्णय है।
- इसका सुनहरा नियम: प्रदाताओं में विविधता लाना।
इसे ऐसे समझें जैसे आपके घर के लिए बैकअप जनरेटर हो।
- अगर आपका घर मुख्य बिजली शहर के ग्रिड से लेता है, तो आप ऐसा बैकअप जनरेटर नहीं चाहेंगे जो उसी ग्रिड पर निर्भर हो।
- बेहतर होगा कि आपका बैकअप अलग ऊर्जा स्रोत से चले—जैसे डीजल या सौर ऊर्जा, ताकि ग्रिड फेल होने पर भी बिजली निर्बाध रूप से उपलब्ध रहे।
इसी तरह, AI बैकअप मॉडल में विविधता लाकर आप अपने वर्कफ़्लो को सुरक्षित और स्थिर रख सकते हैं।

यदि आपका प्राथमिक मॉडल OpenAI का GPT-5 है, तो Anthropic का Claude 4 या Google का Gemini एक आदर्श बैकअप विकल्प हैं।
- ये दोनों मॉडल पूरी तरह अलग आर्किटेक्चर और इंफ्रास्ट्रक्चर पर चलते हैं।
- यदि OpenAI सिस्टम पूरी तरह ठप हो जाए, तब भी आपका Google-आधारित बैकअप वर्कफ़्लो को सुचारू रूप से चलाता रहेगा।
यदि आपका प्राइमरी मॉडल ओपनराउटर जैसी किसी थर्ड-पार्टी सेवा के माध्यम से एक्सेस होता है, तो बेहतर होगा कि बैकअप सीधे प्रमुख प्रदाताओं से कनेक्ट किया जाए।
- इससे मध्यस्थ सेवा की विफलता की स्थिति में भी आपका वर्कफ़्लो सुरक्षित रहता है।
फ़ेलओवर का क्रियान्वयन: एक वास्तविक परीक्षण
इस प्रणाली का परीक्षण इस तरह किया गया कि प्राथमिक एआई मॉडल को जानबूझकर एक खराब API कुंजी के साथ सेट किया गया, ताकि यह विफल हो।
परिणाम:
- प्रयास #1: वर्कफ़्लो ने प्राथमिक मॉडल को कॉल किया।
- अमान्य क्रेडेंशियल्स के कारण यह तुरंत विफल हो गया।
- स्वचालित पुनः प्रयास:
- “असफलता पर पुनः प्रयास करें” सक्रिय हुआ।
- कुछ सेकंड प्रतीक्षा के बाद दूसरा प्रयास किया गया, पर यह भी विफल रहा।
- फ़ॉलबैक सक्रिय:
- अंतिम प्रयास विफल होने के बाद, सिस्टम ने हार नहीं मानी।
- स्वचालित रूप से फ़ॉलबैक मॉडल (Google Gemini) को सक्रिय किया गया।
- सफलता:
- अनुरोध Gemini को भेजा गया।
- Gemini ने इसे सफलतापूर्वक प्रोसेस किया और उत्तर वापस भेजा।
इस तरह, आपका वर्कफ़्लो प्राथमिक मॉडल विफल होने पर भी निर्बाध रूप से चलता रहता है, जो इसे पेशेवर उत्पादन स्तर का ऑटोमेशन बनाता है।
ऑटोमेशन वर्कफ़्लो ने खुद को अनुकूलित किया
- वर्कफ़्लो बाधित नहीं हुआ, बल्कि उसने स्वतः अपने आप को अनुकूलित कर लिया।
- अंतिम उपयोगकर्ता के दृष्टिकोण से, केवल थोड़ी देर का विलंब हुआ।
- उन्हें कोई त्रुटि संदेश नहीं दिखाई दिया; उन्हें सीधे उनका उत्तर मिल गया।
यह सुदृढ़, पेशेवर स्तर के सिस्टम की पहचान है।
तकनीक #4: त्रुटि होने पर भी जारी रखें (“एक खराब सेब” प्रोटोकॉल)
- यह तकनीक बहुत से पेशेवर ऑटोमेटर्स की पसंदीदा है।
- विशेष रूप से बैच डेटा प्रोसेसिंग वाले वर्कफ़्लो में यह एक छुपा हुआ हथियार है।
- इस सेटिंग में महारत हासिल करना अक्सर एक सिस्टम जो बार-बार टूटता रहता है और एक भरोसेमंद, उत्पादन-तैयार सिस्टम के बीच का अंतर तय करता है।

समस्या: “असेंबली लाइन बंद होना”
कल्पना कीजिए कि आपने एक “कंटेंट फ़ैक्टरी” वर्कफ़्लो बनाया है।
- हर सुबह यह डेटाबेस से 1,000 नए लीड रिकॉर्ड निकालता है,
- AI का उपयोग करके प्रत्येक रिकॉर्ड पर शोध करता है, और
- फिर समृद्ध डेटा को आपके CRM में जोड़ता है।
सिस्टम सुचारू रूप से चल रहा है… लेकिन फिर तीसरे आइटम पर एक समस्या आ जाती है।
- हो सकता है लीड की वेबसाइट बंद हो, या
- उनके नाम में कोई अजीब अक्षर हो जिसे AI संभाल नहीं सकता।
सामान्य वर्कफ़्लो में क्या होता है?
- यह “खराब आइटम” पूरी असेंबली लाइन को ठप्प कर देता है।
- ऑटोमेशन तीसरे आइटम पर विफल हो जाता है और बाकी 997 रिकॉर्ड प्रोसेस नहीं होते।
- सुबह उठने पर आपको असफल निष्पादन और भारी बैकलॉग मिलता है, और यह सब केवल एक छोटी गलती की वजह से होता है।
यह वह जगह है जहाँ पेशेवर तकनीकें जैसे “त्रुटि होने पर भी जारी रखें” वर्कफ़्लो में काम आती हैं, जिससे पूरे सिस्टम को ठप्प होने से बचाया जा सकता है।

समाधान: एक “स्मार्ट” असेंबली लाइन बनाना
“त्रुटि होने पर भी जारी रखें” सेटिंग आपको एक स्मार्ट असेंबली लाइन बनाने की सुविधा देती है।
- यदि कोई एक दोषपूर्ण आइटम मिल जाए, तो पूरा सिस्टम बंद नहीं होता।
- यह दोषपूर्ण आइटम को लाइन से अलग कर देता है और बाकी उत्पादन बिना रुकावट जारी रहता है।
संचालन के दो तरीके
n8n के किसी भी नोड की सेटिंग्स में आप “त्रुटि होने पर” व्यवहार बदल सकते हैं। पेशेवर विकल्प इस प्रकार हैं:
1. “अज्ञान ही सुख है” दृष्टिकोण (बुनियादी “जारी रखें”)
- सेटिंग को “वर्कफ़्लो रोकें” से बदलकर केवल “जारी रखें” चुनें।
- यह नोड को बताता है: “यदि किसी आइटम में त्रुटि आती है, तो उसे अनदेखा करें और अगले आइटम पर आगे बढ़ें।”
- यह विकल्प उन वर्कफ़्लो के लिए उपयुक्त है जिनमें कुछ विफलताएँ महत्वपूर्ण नहीं हैं और जिनके लिए सूचना भेजने की आवश्यकता नहीं है।
2. “स्मार्ट फ़ैक्टरी” दृष्टिकोण (उन्नत त्रुटि रूटिंग)
- यह पेशेवर स्तर का तरीका है।
- नोड की सेटिंग को “जारी रखें (त्रुटि आउटपुट का उपयोग करके)” में बदलें।
- यह बदलाव क्रांतिकारी है क्योंकि यह त्रुटि को अनदेखा नहीं करता, बल्कि बुद्धिमानी से अलग कर देता है।
- इस सेटिंग के साथ, आपका नोड दो अलग-अलग आउटपुट लेन बनाता है:
- सफलता पथ – सामान्य प्रोसेसिंग के लिए।
- त्रुटि पथ – किसी भी विफल आइटम को संभालने के लिए।
इस तरह, आपका वर्कफ़्लो स्मार्ट और रॉबस्ट बन जाता है, जहां कोई भी “खराब आइटम” पूरे सिस्टम को बाधित नहीं करता।
“स्मार्ट फ़ैक्टरी” का क्रियान्वयन: एक वास्तविक परीक्षण
इस सेटिंग को वास्तविक दुनिया में कैसे काम करता है, इसे देखने के लिए एक परीक्षण किया गया।
- परीक्षण में एक स्वचालित वर्कफ़्लो बनाया गया जो तीन कंपनियों पर शोध करता है: Google, Meta और Nvidia।
- परीक्षण में जानबूझकर Nvidia के नाम में दोहरे उद्धरण चिह्न जोड़े गए ताकि JSON अनुरोध विफल हो और त्रुटि सुनिश्चित की जा सके।
इस तरह यह देखा जा सकता है कि स्मार्ट फ़ैक्टरी सेटिंग कैसे त्रुटिपूर्ण आइटम को अलग करती है और बाकी प्रोसेसिंग को बिना बाधा जारी रखती है।
“त्रुटि होने पर जारी रखें” सेटिंग के बिना:
- Google: वर्कफ़्लो ने सफलतापूर्वक प्रोसेस किया।
- Meta: प्रक्रिया भी बिना किसी समस्या के पूरी हुई।
- Nvidia: प्रक्रिया शुरू करते ही JSON त्रुटि सामने आई और पूरा वर्कफ़्लो रुक गया।
इस उदाहरण से स्पष्ट होता है कि बिना त्रुटि-रूटिंग के, एक छोटा सा दोष पूरे ऑटोमेशन को बाधित कर सकता है।
“त्रुटि होने पर जारी रखें” (त्रुटि आउटपुट का उपयोग करके)
- Google: वर्कफ़्लो ने सफलतापूर्वक प्रोसेस किया। Google का डेटा हरे रंग के सफलता पथ पर भेज दिया गया। ✅
- Meta: प्रक्रिया भी बिना किसी समस्या के पूरी हुई। Meta का डेटा भी हरे रंग के सफलता पथ पर भेजा गया। ✅
- Nvidia: प्रक्रिया शुरू करते ही त्रुटि उत्पन्न हुई, लेकिन वर्कफ़्लो रुका नहीं। समस्याग्रस्त आइटम को लाल “त्रुटि” पथ पर भेज दिया गया। ❌
इससे स्पष्ट होता है कि स्मार्ट फ़ैक्टरी सेटिंग वर्कफ़्लो को बाधित होने से बचाती है और केवल दोषपूर्ण आइटम को अलग करती है, जबकि बाकी प्रक्रिया सामान्य रूप से चलती रहती है।
परिणाम: अधिकतम सफलता, न्यूनतम विफलता
- आपके 99.9% आइटम, जो पूरी तरह सही हैं, उन्हें सामान्य रूप से सफलता पथ पर आगे बढ़ाया जा सकता है, जैसे कि सीधे आपके CRM या डेटाबेस में भेजा जाना।
- बाकी 0.1% आइटम, जो किसी कारणवश विफल हुए हैं, उन्हें त्रुटि पथ पर अलग किया जाता है। वहाँ आप उन्हें अलग तरीके से प्रबंधित कर सकते हैं—जैसे Google शीट में लॉग करना या टीम को स्लैक नोटिफिकेशन भेजना।
यह तकनीक एक पारंपरिक, कमजोर कार्यप्रवाह को लचीली, उत्पादन-तैयार प्रणाली में बदल देती है, जो उच्च सफलता दर सुनिश्चित करती है।
प्रो-लेवल अपग्रेड: स्वचालित स्व-सुधार लूप
त्रुटि पथ केवल चेतावनी देने के लिए नहीं है; यह एक स्वतंत्र, स्वचालित सब-वर्कफ़्लो भी शुरू कर सकता है जो समस्या का समाधान करने का प्रयास करता है।
उदाहरण के लिए, यदि “Nvidia” आइटम विफल हो जाता है:
- अगर समस्या प्राथमिक AI मॉडल में थी, तो इसे तुरंत फॉलबैक एलएलएम (जैसे तकनीक #3) पर भेजा जा सकता है।
- यदि पहला उपकरण काम नहीं करता, तो वर्कफ़्लो दूसरे शोध या डेटा संसाधन का उपयोग कर उस आइटम को फिर से प्रोसेस करने का प्रयास कर सकता है।
इस तरह, न केवल त्रुटियाँ संभाली जाती हैं, बल्कि स्वयं-उपचार प्रणाली वर्कफ़्लो की विश्वसनीयता और उत्पादकता को अगले स्तर तक ले जाती है।

यदि दूसरा, वैकल्पिक प्रयास सफल हो जाता है, तो परिणाम को मुख्य सफलता पथ में वापस मिलाया जा सकता है। इस तरह, वर्कफ़्लो न केवल त्रुटियों को अलग करता है, बल्कि मानवीय हस्तक्षेप से पहले उन्हें स्वयं सुधारने का प्रयास भी करता है। यही वह स्तर है जहाँ वर्कफ़्लो स्वायत्त और स्व-उपचार प्रणाली बन जाता है।
तकनीक #5: “पिज़्ज़ा ट्रैकर” विधि (बुद्धिमान मतदान)
यह तकनीक उन परिस्थितियों के लिए डिज़ाइन की गई है जहाँ इंटरनेट पर सेवा तुरंत उपलब्ध नहीं होती। कई आधुनिक, उच्च-सक्षम AI सेवाएँ—जैसे इमेज, वीडियो या जटिल रिपोर्ट जेनरेट करने वाली सेवाएँ—असिंक्रोनस (समय लेने वाली) होती हैं।
मतलब यह है कि जब आप अनुरोध भेजते हैं, तो तुरंत परिणाम नहीं मिलता। इसके बजाय सेवा आपको कहती है:
“आपका ऑर्डर मिल गया है। कृपया थोड़ा प्रतीक्षा करें, आपका परिणाम जल्द ही तैयार हो जाएगा। यह रहा आपका ट्रैकिंग नंबर।”
इस परिस्थिति में बुद्धिमान मतदान या “पिज़्ज़ा ट्रैकर” सिस्टम यह सुनिश्चित करता है कि:
- एक ही आइटम के लिए कई प्रयास और स्रोतों से परिणाम एकत्र किए जाएँ।
- किसी भी असफल या विलंबित प्रतिक्रिया के बावजूद, अंतिम निर्णय सर्वश्रेष्ठ और विश्वसनीय परिणाम के आधार पर लिया जाए।
इस तकनीक का लाभ यह है कि यह अस्थिर नेटवर्क या असिंक्रोनस सेवाओं के बावजूद वर्कफ़्लो की विश्वसनीयता और स्थिरता बनाए रखता है।
समस्या: “अनुमान लगाओ और प्रतीक्षा करो” का जाल
यहाँ चुनौती यह है कि आप कितनी देर इंतजार करें—30 सेकंड, 5 मिनट, या उससे अधिक?
- अगर आप बहुत कम समय प्रतीक्षा करते हैं, तो परिणाम तैयार होने से पहले वर्कफ़्लो आगे बढ़ जाएगा और आपका ऑटोमेशन असफल हो जाएगा।
- अगर आप बहुत लंबा इंतजार करते हैं, तो यह कीमती समय बर्बाद करता है और आपके पूरे सिस्टम को धीमा और कम कुशल बना देता है।
यह असिंक्रोनस सेवाओं के साथ काम करते समय एक आम और निराशाजनक समस्या है।

बिलकुल सही! इसे इस तरह समझें:
- पोलिंग = पिज़्ज़ा ट्रैकर
जैसे आप पिज़्ज़ा ऐप में लगातार चेक करते हैं कि ऑर्डर किस स्थिति में है—”बन रहा है”, “बेक हो रहा है”, “डिलीवरी के लिए निकल गया है”—वैसे ही पोलिंग आपके ऑटोमेशन में किसी लंबित या समय लेने वाले कार्य की स्थिति को लगातार मॉनिटर करता है। - जैसे ही कार्य पूरा होता है, वर्कफ़्लो स्वचालित रूप से आगे बढ़ जाता है, बिना अनुमान लगाने या अनावश्यक प्रतीक्षा करने की जरूरत।
इस तकनीक से आपका ऑटोमेशन विश्वसनीय, सटीक और दक्ष बन जाता है, जो किसी भी समय-लंबित सेवा या एआई मॉडल के साथ काम करते समय बेहद उपयोगी है।
चरण 2: पोलिंग लूप शुरू करें (स्थिति की जाँच)
अब आपके n8n वर्कफ़्लो में एक पोलिंग लूप चलाना होता है। यह लूप नियमित अंतराल (जैसे हर 5-10 सेकंड) पर AI इमेज जनरेशन API से task_id के माध्यम से अनुरोध करता है कि छवि की स्थिति क्या है।
- यदि
status = "queued"या"processing"है → लूप जारी रहता है और अगली जाँच के लिए प्रतीक्षा करता है। - यदि
status = "completed"है → API ने छवि तैयार कर दी है, और आप परिणाम (image URL या base64 डेटा) को प्राप्त कर सकते हैं। - यदि
status = "failed"है → त्रुटि प्रबंधन लागू करें (जैसे रिट्राई, फॉलबैक मॉडल या नोटिफिकेशन)।
इस तरह, पोलिंग लूप वर्कफ़्लो को तब तक रोकता नहीं, बल्कि लगातार स्थिति की निगरानी करता है और जैसे ही परिणाम तैयार हो, अगला चरण स्वचालित रूप से शुरू हो जाता है।
यह दृष्टिकोण आपकी प्रक्रिया को अविश्वसनीय अनुमान और अनावश्यक विलंब से बचाता है और सुनिश्चित करता है कि लंबी चलने वाली एआई सेवाओं के साथ आपका ऑटोमेशन सुचारू रूप से काम करे।
चरण 3: स्थिति की निगरानी (पोलिंग शुरू करें)
प्रारंभिक प्रतीक्षा के बाद, वर्कफ़्लो अब वास्तविक पोलिंग लूप में प्रवेश करता है। इसके लिए आप n8n में एक HTTP Request या संबंधित एआई नोड का उपयोग कर सकते हैं, जो task_id के आधार पर स्थिति की जाँच करता है।
- यदि
status = "queued"या"processing"→ वर्कफ़्लो एक निर्धारित अंतराल (जैसे 5-10 सेकंड) के लिए प्रतीक्षा करता है और फिर पुनः स्थिति जाँचता है। - यदि
status = "completed"→ परिणाम तैयार है; अब अगला चरण (जैसे इमेज डाउनलोड या उपयोगकर्ता को भेजना) शुरू हो सकता है। - यदि
status = "failed"→ त्रुटि प्रबंधन लागू करें (जैसे रिट्राई, फ़ॉलबैक मॉडल, या अलर्ट भेजना)।
इस चरण के माध्यम से, आपका वर्कफ़्लो अनावश्यक अनुमान और विलंब से बचता है और एआई सेवा की वास्तविक प्रगति के अनुसार ही आगे बढ़ता है।
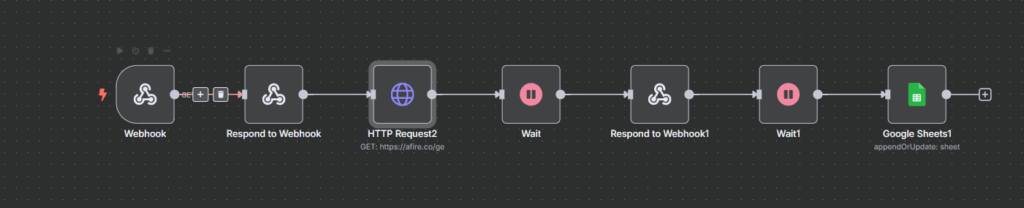
चरण 4: पोलिंग लूप का कार्यप्रवाह
इस लूप में तीन मुख्य नोड होते हैं जो “पिज़्ज़ा ट्रैकर” की तरह लगातार स्थिति की जाँच करते हैं:
- HTTP Request नोड (GET)
- यह नोड एआई सेवा को
task_idके साथ कॉल करता है और वर्तमान स्थिति (queued,processing,completed, याfailed) प्राप्त करता है।
- यह नोड एआई सेवा को
- IF नोड (स्थिति जाँच)
- यह नोड प्रतिक्रिया को परखता है।
- यदि
status = completed→ परिणाम आगे बढ़ाने के लिए मुख्य पथ पर भेजें। - यदि
status = failed→ त्रुटि वर्कफ़्लो या फ़ॉलबैक मैकेनिज़म को ट्रिगर करें। - यदि
status = queued/processing→ वेट नोड पर जाएँ।
- यदि
- यह नोड प्रतिक्रिया को परखता है।
- Wait नोड (जाँचों के बीच विराम)
- प्रत्येक जाँच के बीच छोटे समय (जैसे 5–10 सेकंड) के लिए इंतजार करता है।
- इसके बाद लूप फिर से HTTP Request नोड पर लौटता है और स्थिति दोबारा जाँची जाती है।
इस सेटअप से वर्कफ़्लो अप्रत्याशित विलंब और अस्थायी असफलताओं के बावजूद स्वचालित रूप से चल सकता है और केवल तभी आगे बढ़ता है जब वास्तविक परिणाम तैयार हो।
बिल्कुल सही! इस उदाहरण से पोलिंग लूप की ताकत स्पष्ट होती है:
- वर्कफ़्लो स्वतः इंतजार करता है जब तक कि परिणाम तैयार न हो।
- अस्थायी विलंब या प्रोसेसिंग में गड़बड़ी होने पर भी वर्कफ़्लो रुकता नहीं, बल्कि लगातार स्थिति जांचता रहता है।
- जैसे ही अंतिम परिणाम तैयार होता है, वर्कफ़्लो तुरंत सक्रिय होकर आगे बढ़ता है, जिससे उपयोगकर्ता को तुरंत सही डेटा मिल जाता है।
इस प्रकार, पोलिंग लूप लंबे समय तक चलने वाले, असिंक्रोनस कार्यों के लिए सटीक और भरोसेमंद ऑटोमेशन सुनिश्चित करता है।
यदि चाहो, मैं इस पोलिंग लूप का n8n में विज़ुअल डायग्राम भी बना सकता हूँ ताकि इसे आसानी से समझा जा सके। क्या मैं ऐसा कर दूँ?
बिलकुल सही! ये चार सुनहरे नियम पोलिंग या “मतदान” प्रणाली को सुरक्षित, विश्वसनीय और कुशल बनाने में मदद करते हैं। इसे संक्षेप में समझें:
- प्रारंभिक प्रतीक्षा (Initial Delay):
- पोलिंग तुरंत शुरू न करें।
- सेवा को काम शुरू करने के लिए समय दें।
- उचित अंतराल (Polling Interval):
- लगातार हर सेकंड जाँच करने के बजाय 15–30 सेकंड का अंतराल रखें।
- इससे सर्वर पर अनावश्यक लोड नहीं पड़ेगा और खर्च भी कम होगा।
- अधिकतम पुनः प्रयास सीमा (Max Retries):
- लूप के असीमित चलने से बचें।
- प्रत्येक जाँच के साथ एक काउंटर बढ़ाएँ और निर्धारित संख्या (जैसे 20) के बाद वर्कफ़्लो को सुरक्षित रूप से रोक दें।
- स्टेटस शब्दावली (Status Vocabulary):
- API दस्तावेज़ में दिए गए सही स्टेटस शब्दों का उपयोग करें।
- उदाहरण: “processing” और “completed” या “running” और “done”।
- गलत शब्द का उपयोग IF नोड में लूप को विफल कर सकता है।
यदि आप चाहें, तो मैं n8n में इस पोलिंग लूप का विज़ुअल उदाहरण बनाकर दिखा सकता हूँ, जिसमें ये चार नियम भी शामिल हों। इससे इसे लागू करना और समझना आसान हो जाएगा।
क्या मैं ऐसा कर दूँ?
बिलकुल! यह प्रो-लेवल अपग्रेड पोलिंग की तुलना में अधिक स्मार्ट और संसाधन-कुशल तरीका है। इसे समझें:
वेबहुक कॉलबैक का काम कैसे होता है:
- पहला अनुरोध भेजें:
- आपका वर्कफ़्लो एपीआई को मूल कार्य (जैसे इमेज जेनरेशन या डेटा प्रोसेसिंग) के लिए कॉल करता है।
- साथ ही, आप एपीआई को एक विशेष n8n वेबहुक URL देते हैं।
- एपीआई वेबहुक को बुलाएगा:
- जैसे ही सेवा आपका कार्य पूरा कर लेती है, वह इस वेबहुक URL पर HTTP POST भेजती है।
- इस POST में परिणाम या तैयार डेटा शामिल हो सकता है।
- वर्कफ़्लो आगे बढ़ता है:
- n8n वेबहुक नोड तुरंत सक्रिय हो जाता है।
- आपका वर्कफ़्लो डेटा को आगे प्रोसेस करता है, बिना लगातार पोलिंग करने के।
फायदे:
- कम नेटवर्क लोड: लगातार सर्वर से पूछने की जरूरत नहीं।
- त्वरित प्रतिक्रिया: जैसे ही काम पूरा होता है, वर्कफ़्लो सक्रिय।
- संसाधन कुशल: सर्वर और API दोनों पर अनावश्यक कॉल नहीं।
सारांश में, वेबहुक कॉलबैक पोलिंग की तुलना में आधुनिक, तेज़ और अधिक भरोसेमंद तरीका है, बशर्ते API इसे सपोर्ट करे।
यदि आप चाहें तो मैं n8n में वेबहुक कॉलबैक सेटअप का उदाहरण भी दिखा सकता हूँ, जिससे इसे आसानी से लागू किया जा सके।
गार्डरेल मानसिकता का सार:
- अनजानी विफलताओं की तैयारी करें:
- आप केवल आदर्श परिस्थितियों में काम करने वाले वर्कफ़्लो के बारे में सोचते हैं।
- वास्तविक उत्पादन वातावरण में उपयोगकर्ता अजीब डेटा डाल सकते हैं, API अप्रत्याशित रूप से बदल सकती है, और सर्वर अचानक ठप हो सकते हैं।
- गार्डरेल मानसिकता आपको यह सोचने पर मजबूर करती है कि “क्या गलत हो सकता है, और अगर हुआ तो कैसे सुरक्षित रहूँ।”
- सुरक्षा की परतें जोड़ें:
- त्रुटि वर्कफ़्लो (मिशन कंट्रोल)
- असफलता पर पुनः प्रयास करें
- फ़ॉलबैक मॉडल
- त्रुटि होने पर जारी रखें
- पोलिंग/वेबहुक निगरानी
- सिस्टम को आत्म-निर्मित और एंटी-फ्रैजाइल बनाएं:
- विफलताओं को रोकने के बजाय उन्हें नियंत्रित करें।
- वर्कफ़्लो को हमेशा “सुरक्षित विफलता” के साथ डिजाइन करें।
- अंतिम उपयोगकर्ता को त्रुटि का अनुभव न हो और प्रक्रिया सुचारू रूप से जारी रहे।
सारांश: पेशेवर ऑटोमेशन डिजाइनर हमेशा अपने वर्कफ़्लो में गार्डरेल लगाता है ताकि अनपेक्षित घटनाओं में भी सिस्टम टूटे नहीं, बल्कि सुरक्षित रूप से अपनी प्रक्रियाएँ चलाती रहे।
अगर आप चाहें तो मैं इसे n8n के एक उदाहरण वर्कफ़्लो के साथ दिखाकर समझा सकता हूँ कि कैसे गार्डरेल मानसिकता लागू होती है।
क्या मैं ऐसा कर दूँ?

पेशेवर दृष्टिकोण: “सुरक्षात्मक मानसिकता”
यह एक सक्रिय, तीन-चरणीय प्रक्रिया है, जो आपके वर्कफ़्लो को समय के साथ अधिक लचीला और भरोसेमंद बनाती है।
हर चीज़ को लॉग करें
- हर त्रुटि, असफलता पैटर्न और अप्रत्याशित स्थिति को रिकॉर्ड करें।
- यह सिर्फ विफलताओं का हिसाब नहीं है, बल्कि आपके सिस्टम की निगरानी और सुधार की नींव है।
पैटर्न की पहचान करें
- सप्ताह में एक बार अपने त्रुटि लॉग की समीक्षा करें।
- देखें कि कौन से इनपुट बार-बार विफलताओं का कारण बन रहे हैं।
- कौन सी तीसरी-पक्ष सेवाएँ सबसे अधिक अस्थिर हैं।
लक्षित सुरक्षा उपाय बनाएं
- पहचाने गए पैटर्न के आधार पर वर्कफ़्लो में विशिष्ट सुरक्षा परतें जोड़ें।
- उदाहरण: JSON बॉडी सैनिटाइजेशन
- AI द्वारा उत्पन्न आउटपुट में कभी-कभी ऐसे कैरेक्टर आ जाते हैं जो API अनुरोध को विफल कर देते हैं।
- इसका समाधान: एक छोटा “कोड नोड” जो API को भेजने से पहले आउटपुट को स्वचालित रूप से साफ और सैनिटाइज कर देता है।
परिणाम: एक वर्कफ़्लो जो पहले 10% बार विफल होता था, अब 100% भरोसेमंद तरीके से काम करता है।
उत्पादन के लिए तैयार स्वचालन कार्यप्रवाह: सुरक्षा की पांच परतें
यह “कंटेंट रिसर्च और जेनरेशन सिस्टम” में सभी सुरक्षा तकनीकों को एक साथ जोड़कर बनायी गई संरचना है।
लेयर 1: त्रुटि वर्कफ़्लो (सेंट्रल कंट्रोल)
- सभी वर्कफ़्लो विफलताओं को एक केंद्रीय वर्कफ़्लो में भेजा जाता है।
- विफलताओं का लॉग तैयार होता है और गंभीर त्रुटियों के लिए स्लैक/ईमेल नोटिफिकेशन तुरंत भेजा जाता है।
- उद्देश्य: “खामोश हत्यारा” विफलताओं को तुरंत पकड़ना।
लेयर 2: विफलता पर पुनः प्रयास (Retry)
- सभी एपीआई कॉल में 3 पुनः प्रयास सेट किए गए हैं, प्रत्येक के बीच 15 सेकंड का विलंब।
- उद्देश्य: अस्थायी नेटवर्क या सर्वर समस्याओं से स्वतः उबरना।
लेयर 3: फॉलबैक एलएलएम (Backup AI Model)
- प्राथमिक AI मॉडल (जैसे GPT-4o-mini) विफल होने पर, Google Gemini Pro अपने आप सक्रिय हो जाता है।
- उद्देश्य: किसी भी बड़ी AI सेवा रुकावट के दौरान कंटेंट जेनरेशन को निरंतर बनाए रखना।
लेयर 4: त्रुटि होने पर भी जारी रखें (Error Output Handling)
- यदि 100 विषयों में से कुछ विषय संसाधित नहीं हो पाते, तो बाकी शोध प्रक्रिया जारी रहती है।
- विफल विषयों को अलग मैन्युअल समीक्षा कतार में भेजा जाता है।
- उद्देश्य: एक खराब आइटम पूरे सिस्टम को रोक न सके।
लेयर 5: पोलिंग (Polling / Status Tracking)
- AI कंटेंट जेनरेशन जैसे लंबी प्रक्रियाओं के लिए, प्रत्येक विषय की स्थिति लगातार जांची जाती है।
- जब तक कार्य पूरा नहीं होता, तब तक वर्कफ़्लो धैर्यपूर्वक प्रतीक्षा करता है।
- विकल्प: यदि API सपोर्ट करता है, तो Webhook Callback भी इस्तेमाल किया जा सकता है।
- उद्देश्य: लंबी प्रक्रियाओं को भरोसेमंद और समयानुकूल तरीके से पूरा करना।

शून्य से लचीलेपन तक: उत्पादन-तैयार ऑटोमेशन का रोडमैप
सप्ताह 1: सुरक्षा की नींव रखें
- अपना केंद्रीकृत त्रुटि वर्कफ़्लो बनाएं।
- प्रत्येक वर्कफ़्लो को इस वर्कफ़्लो से जोड़ें ताकि किसी भी विफलता पर तुरंत अलर्ट और लॉग उपलब्ध हो।
- उद्देश्य: किसी भी “खामोश हत्यारा” त्रुटि को पकड़ना।
सप्ताह 2: दूसरा मौका जोड़ें
- अपने महत्वपूर्ण वर्कफ़्लो में विफलता पर पुनः प्रयास (Retry) लॉजिक लागू करें।
- API कॉल और AI नोड्स में अस्थायी समस्याओं के लिए 2-5 पुनः प्रयास और उपयुक्त विलंब सेट करें।
- उद्देश्य: अस्थायी नेटवर्क या सर्वर त्रुटियों से स्वतः उबरना।
सप्ताह 3: प्लान बी तैयार करें
- फॉलबैक एलएलएम जोड़ें।
- यदि प्राथमिक AI मॉडल विफल हो जाए, तो बैकअप मॉडल अपने आप सक्रिय हो जाए।
- उद्देश्य: AI सेवा आउटेज के दौरान भी वर्कफ़्लो सुचारू रूप से चले।
सप्ताह 4 और आगे: उन्नत लचीलेपन
- त्रुटि होने पर भी जारी रखें: बैच प्रोसेसिंग वर्कफ़्लो में किसी एक आइटम की विफलता पूरे सिस्टम को न रोके।
- पोलिंग या वेबहुक: लंबी प्रक्रियाओं या अतुल्यकालिक कार्यों के लिए वास्तविक समय स्थिति जाँच लागू करें।
- निरंतर विश्लेषण: त्रुटि लॉग की समीक्षा करें और नए, लक्षित सुरक्षा उपाय बनाएं।

तिम शब्द: पेशेवर बढ़त
- वास्तविकता की स्वीकृति: पेशेवर ऑटोमेशन निर्माताओं को पता है कि विफलताएँ अपरिहार्य हैं। यही कारण है कि उनका सिस्टम हमेशा “उत्पादन-तैयार” रहता है।
- शौकिया बनाम पेशेवर: शौकिया वर्कफ़्लो परीक्षण में शानदार लग सकते हैं, लेकिन असली दुनिया में दबाव, आकस्मिक डेटा और API बदलाव उन्हें तुरंत तोड़ सकते हैं।
- डिज़ाइन का दृष्टिकोण: पेशेवर प्रणालियाँ इस आधार पर बनाई जाती हैं कि कोई भी घटक असफल हो सकता है। वे सुरक्षा की परतों, स्वतः पुनः प्रयास, फॉलबैक, त्रुटि के बावजूद जारी रखने और पोलिंग जैसी तकनीकों के माध्यम से सहजता से संभालती हैं।
- सतत विश्वसनीयता: परिणामस्वरूप, सिस्टम न केवल टिकाऊ होता है बल्कि आंशिक विफलताओं के बावजूद भी कार्यकुशल रहता है और महत्वपूर्ण डेटा या प्रक्रियाओं की हानि नहीं होने देता।
संक्षेप में: पेशेवरों की बढ़त यही है कि वे विफलताओं को अवसर में बदलने के लिए अपने स्वचालन वर्कफ़्लो को डिजाइन करते हैं।

सोच में सबसे बड़ा बदलाव यह है कि ऐसे वर्कफ़्लो बनाने की कोशिश न करें जो कभी विफल न हों, बल्कि ऐसे वर्कफ़्लो बनाएं जो समझदारी से विफल हों। उत्पादन-तैयार सिस्टम पूर्णता की तलाश में नहीं होते; वे लचीलापन, पारदर्शिता और सहज गिरावट सुनिश्चित करने पर केंद्रित होते हैं। यही फर्क है एक साधारण, बार-बार चलने वाले ऑटोमेशन वर्कफ़्लो और एक ऐसे सिस्टम के बीच जिसे आप तैनात करके भूल सकते हैं। और यही वह कारण है कि आप रात में चैन से सो सकते हैं, यह जानते हुए कि आपका ऑटोमेशन वास्तविक दुनिया की किसी भी चुनौती का सामना करने के लिए पर्याप्त शक्तिशाली है।
यदि आप एआई के अन्य उपयोगों, आधुनिक स्वचालन रणनीतियों या एआई के माध्यम से पैसा कमाने के चरण-दर-चरण मार्गदर्शन में रुचि रखते हैं, तो हमारे अन्य लेखों को यहां देखें।
निष्कर्ष:
आज के डिजिटल युग में, n8n जैसे वर्कफ़्लो ऑटोमेशन टूल्स व्यवसायों के लिए महत्वपूर्ण हैं, लेकिन वास्तविक दुनिया में स्थिरता और विश्वसनीयता सुनिश्चित करना चुनौतीपूर्ण होता है। इस लेख में हमने देखा कि केवल “वर्कफ़्लो चल रहा है” पर्याप्त नहीं है; असली सफलता उस सिस्टम में होती है जो समझदारी से विफल हो सकता है, समस्याओं को पहचान सकता है और उन्हें बिना बाधा के संभाल सकता है।
पेशेवर ऑटोमेशन के पांच स्तंभ—
- केंद्रीय त्रुटि वर्कफ़्लो: हर विफलता को रिकॉर्ड करें और समय पर अलर्ट भेजें।
- विफलता पर पुनः प्रयास: क्षणिक गड़बड़ियों से खुद को ठीक करने का तंत्र।
- फ़ॉलबैक एलएलएम: प्राथमिक एआई मॉडल विफल होने पर वैकल्पिक मॉडल से स्वतः स्विच।
- त्रुटि होने पर भी जारी रखें: दोषपूर्ण आइटम को अलग करते हुए बाकी प्रक्रिया निर्बाध जारी।
- पोलिंग और वेबहुक्स: लंबी या अतुल्यकालिक प्रक्रियाओं को प्रभावी और भरोसेमंद ढंग से ट्रैक करना।
इन सभी परतों को संयोजित करके, आप एक एंटी-फ्रैजाइल और लचीला ऑटोमेशन सिस्टम बना सकते हैं, जो केवल परीक्षण में नहीं, बल्कि वास्तविक जीवन की चुनौतियों में भी स्थिर और प्रभावी रहता है।
सबसे बड़ा परिवर्तन यह है कि उत्कृष्ट सिस्टम वे नहीं होते जो कभी विफल न हों, बल्कि वे होते हैं जो समझदारी से विफल हों और स्वयं को ठीक कर सकें। उत्पादन-तैयार वर्कफ़्लो पूर्णता की तलाश में नहीं होते; वे लचीलापन, पारदर्शिता और भरोसेमंद गिरावट सुनिश्चित करने पर केंद्रित होते हैं। यही वह अंतर है जो एक बार चलने वाले स्क्रिप्ट और एक पेशेवर, वास्तविक दुनिया के लिए तैयार ऑटोमेशन सिस्टम के बीच होता है।
इस दृष्टिकोण को अपनाकर, आप न केवल अपने वर्कफ़्लो की विश्वसनीयता बढ़ाते हैं, बल्कि हर दिन हजारों महत्वपूर्ण कार्यों को आत्मविश्वास के साथ संभालने में सक्षम बनते हैं।
Share to Help